An analysis of nearly 10,000 healthcare search results found an unexpected pattern: sites ranking #1 tend to have fewer entity mentions but significantly more content depth than lower-ranking competitors.
Google’s understanding of entities the people, places, concepts, and things that make up the knowledge graph has become central to how the search engine interprets content. This has led many SEO practitioners to focus on “entity coverage”: mentioning relevant topics, treatments, conditions, and credentials to signal topical authority.
But does comprehensive entity coverage actually correlate with better rankings?
To test this, we analyzed 999 healthcare search queries, examining 9,879 search results across 2,110 domains and crawling 25,781 individual pages. The findings challenge some common assumptions about what separates Position #1 from the rest of the first page.
Methodology
Data Collection
The dataset focused on the healthcare and addiction treatment vertical:
Queries: 999 healthcare-focused search queries, split between local intent (70%, such as “rehab centers in Phoenix”) and informational intent (30%, such as “signs of alcohol withdrawal”).
SERP Data: Positions 1-10 for each query, collected via ScrapingDog API in December 2025.
Crawling: Up to 15 pages per domain using the Firecrawl API, capturing page content, word counts, and metadata.
Entity Categories
Four categories of entities were tracked using keyword-based detection:
Treatment modalities (38 terms): detox, inpatient, outpatient, MAT, therapy, residential, PHP, IOP, holistic, faith-based, and similar treatment-related terminology.
Conditions (34 terms): alcohol, opioid, heroin, fentanyl, cocaine, mental health, depression, anxiety, PTSD, and related condition terminology.
Credentials (27 terms): licensed, accredited, JCAHO, CARF, board certified, insurance accepted, and trust signals.
Geographic signals: All 50 US states, major cities, and proximity terms like “near me.”
Sample Sizes
The final analysis included 9,879 search results from 2,110 unique domains, with 25,781 pages crawled. For matched-sample comparisons, 317 Position #1 domains were compared against a randomly selected sample of 317 Position #10 domains.
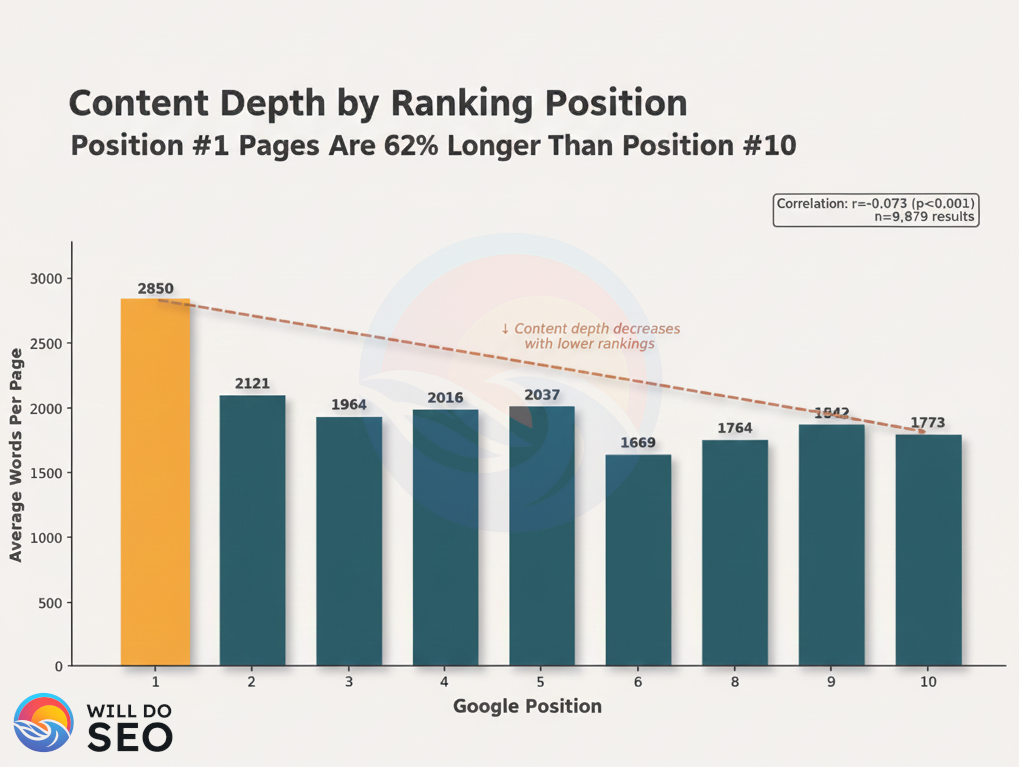
Finding #1: Position #1 Sites Have More Content Depth
The first pattern was straightforward: higher-ranking pages tend to be longer.
| Position | Avg Words/Page |
|---|---|
| #1 | 2,850 |
| #2 | 2,121 |
| #3 | 1,964 |
| #6 | 1,669 |
| #10 | 1,773 |
Position #1 pages average 61% more words than Position #10 pages. The drop-off is sharpest between positions 1 and 2, with a 25% decrease.
Statistical Details
Spearman correlation: r = -0.073 (negative because lower position numbers indicate better rankings)
p-value: p < 0.001 ✓ (statistically significant)
Effect size: Small (r² = 0.005, explaining 0.5% of variance)
Sample: n = 9,879 search results
The correlation is statistically significant but modest in magnitude. Content depth alone explains only a small fraction of ranking variation but the pattern is consistent across the dataset.
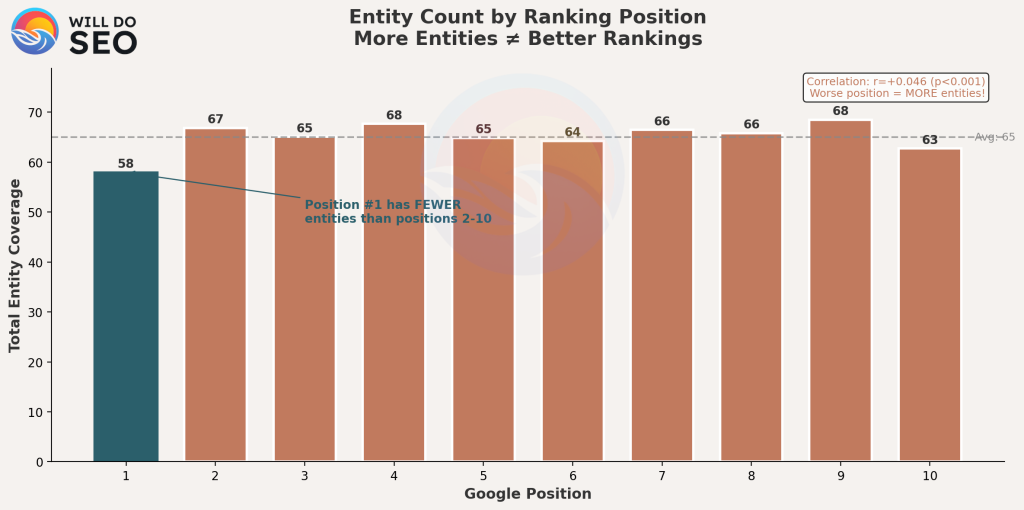
Finding #2: Position #1 Sites Have Fewer Entity Mentions
This finding was unexpected. Rather than showing the most comprehensive entity coverage, Position #1 results had the lowest average entity count in the dataset.
| Position | Avg Entity Count |
|---|---|
| #1 | 58 |
| #2 | 67 |
| #3 | 65 |
| #4 | 68 |
| #9 | 68 |
| #10 | 63 |
Position #1 results showed fewer total entity mentions than any other position running counter to the hypothesis that comprehensive topic coverage improves rankings.
Statistical Details
Spearman correlation: r = +0.046 (positive, meaning more entities associated with worse rankings)
p-value: p < 0.001 ✓ (statistically significant)
Effect size: Very small (r² = 0.002, explaining 0.2% of variance)
Important caveat: When comparing Position #1 and Position #10 means directly using a t-test, the difference was not statistically significant (p = 0.734). The correlation exists across all positions but the endpoint comparison shows considerable overlap.
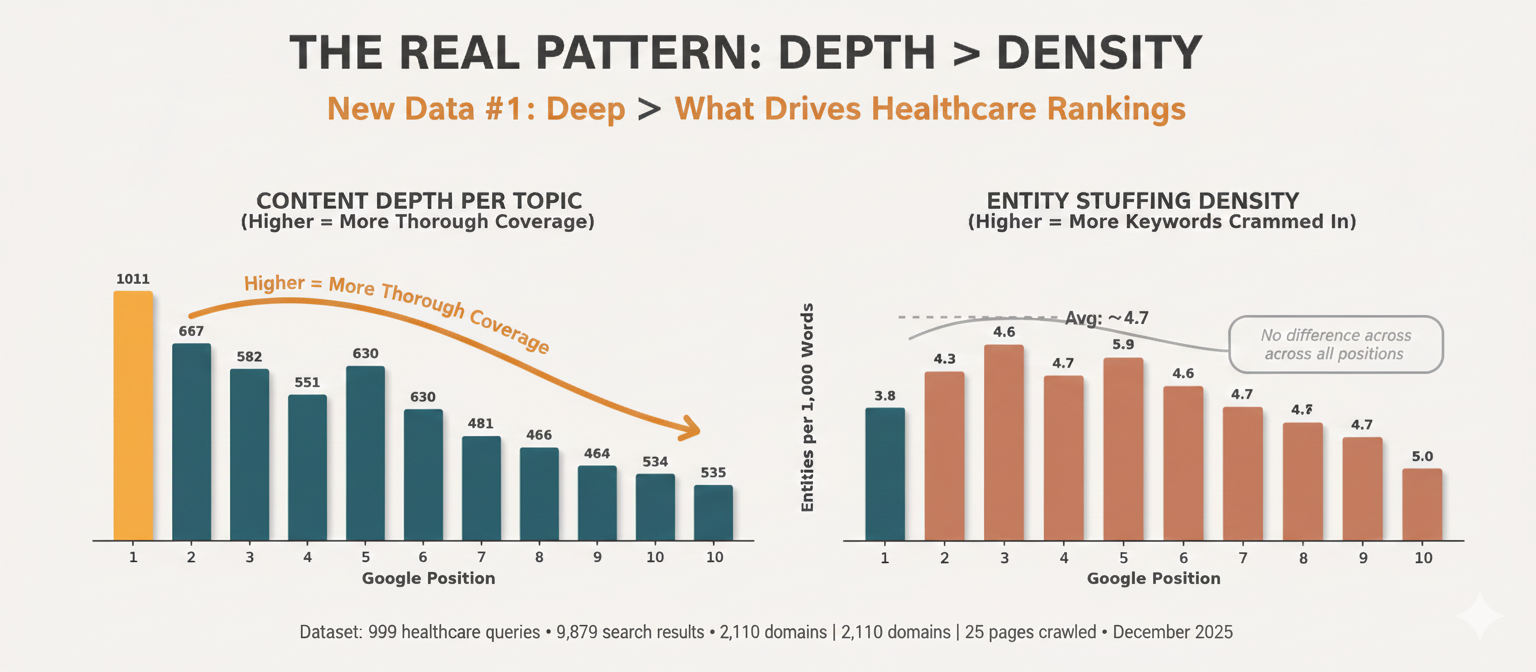
Finding #3: Depth Over Breadth
Combining these two findings reveals a clearer pattern. Position #1 sites tend to have:
Fewer entity mentions combined with more total words. This suggests they’re writing more deeply about fewer topics rather than briefly mentioning everything.
Position #10 sites show the inverse: more entity mentions combined with fewer words, suggesting shallow coverage of many topics.
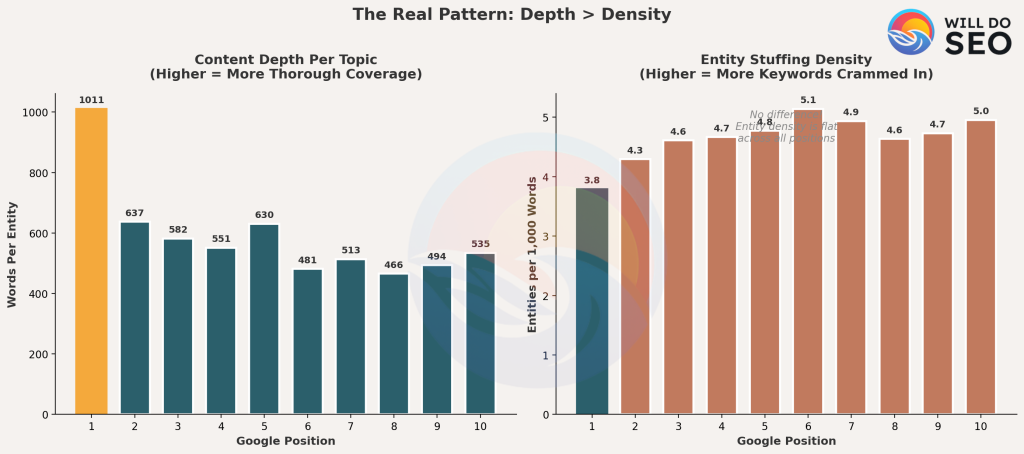
To quantify this, we calculated “words per entity” a rough measure of content depth per topic:
| Position | Words Per Entity |
|---|---|
| #1 | 1,011 |
| #2 | 637 |
| #3 | 582 |
| #5 | 630 |
| #8 | 466 |
| #10 | 535 |
Position #1 results average 89% more words per entity than Position #10 results.
Statistical Details
t-test comparing Position #1 vs #10: t = 4.21, p < 0.001 ✓
This represents a meaningful effect size the clearest signal in the dataset.
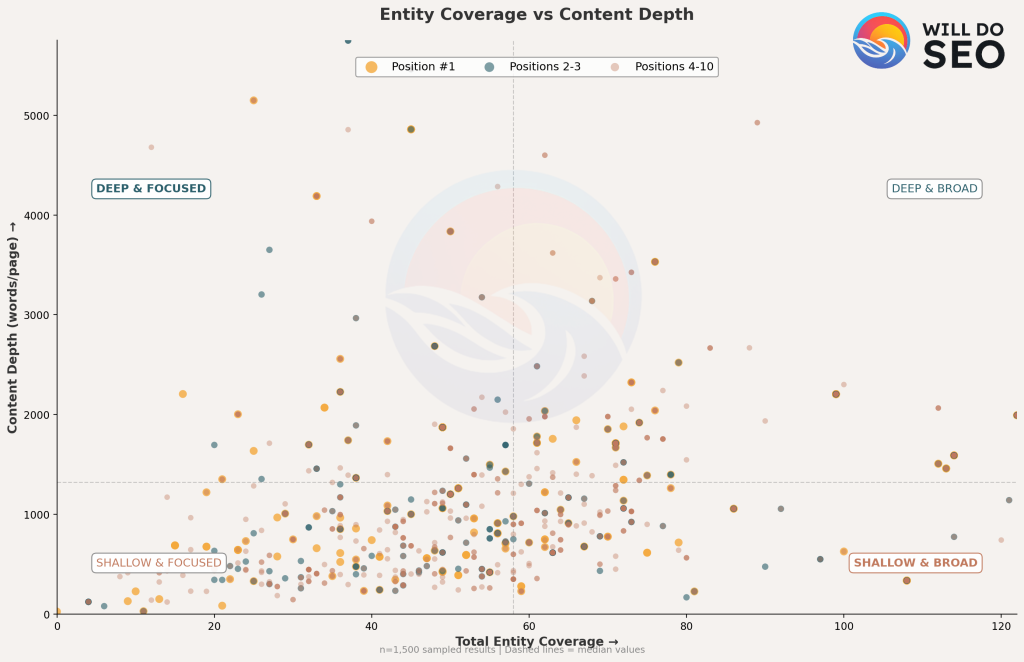
The scatter plot shows Position #1 results clustering toward the “Deep & Focused” quadrant (upper-left: more words, fewer entities), while lower positions spread more evenly or cluster toward “Shallow & Broad” (lower-right: fewer words, more entities).
The pattern suggests: depth over breadth.
Entity Type Breakdown
Testing each entity category separately revealed consistent patterns:
| Entity Type | Correlation | p-value | Significant? |
|---|---|---|---|
| Treatment modalities | r = +0.063 | < 0.001 | ✓ Yes (more = worse rank) |
| Conditions covered | r = +0.049 | < 0.001 | ✓ Yes (more = worse rank) |
| Credential signals | r = +0.012 | 0.234 | ✗ No effect |
| Geographic terms | r = -0.018 | 0.074 | ✗ No effect |
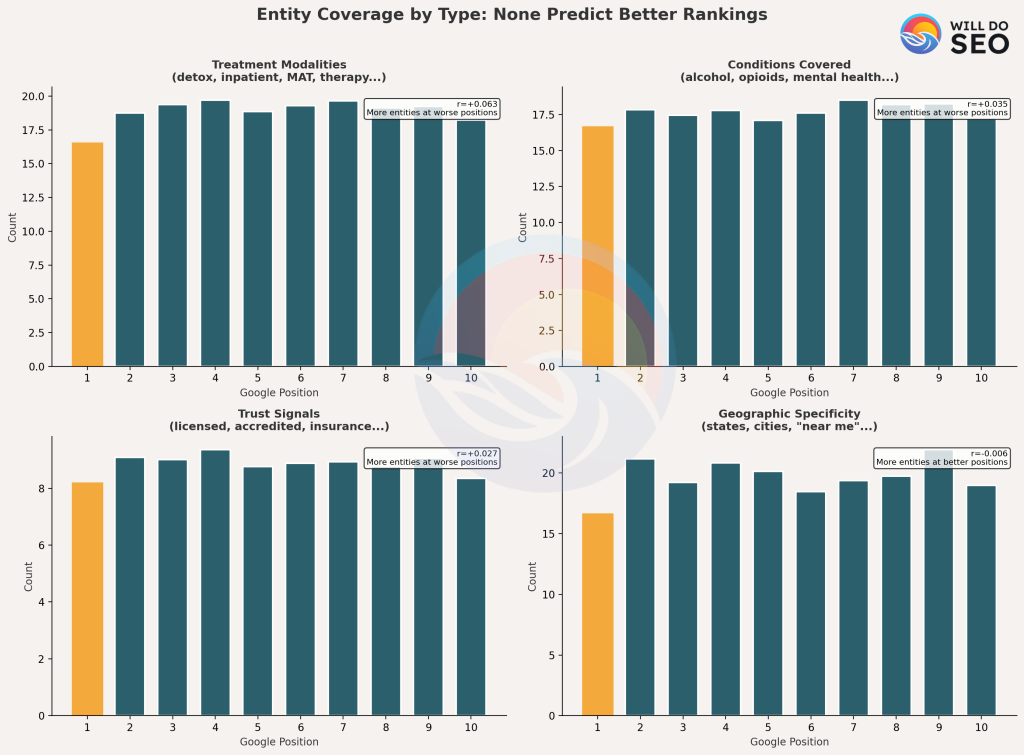
No entity type showed a positive correlation with better rankings. Treatment modalities and condition mentions showed weak but significant negative correlations more mentions associated with worse rankings. Credential and geographic signals showed no meaningful relationship either direction.
A Conceptual Hierarchy
Based on this analysis, a three-tier hierarchy may explain how these factors interact:
Tier 1: Entity Coverage (Foundation)
Entity coverage appears flat across all ranking positions. Sites ranking #1 and #10 mention similar numbers of treatment types, conditions, and credentials. This suggests entity coverage may be a baseline requirement necessary to rank at all for healthcare queries but not a differentiator between positions.
Tier 2: Content Depth (Competitive Advantage)
Content depth shows a clearer gradient. Position #1 pages have 61% more words than Position #10. This may be what separates page-one results from deeper positions.
Tier 3: Query-Specific Optimization (The #1 Spot)
The combination of focused depth (fewer entities, more words per entity) may be what separates Position #1 from Positions #2-3. Sites winning the top spot appear to go deep on their specific topic rather than trying to cover everything.

Possible Interpretations
Several explanations could account for these patterns:
1. Depth signals expertise
Google may interpret thorough coverage of a specific topic as a stronger signal of authority than broad but shallow mentions of many topics. This would align with the E-E-A-T framework’s emphasis on demonstrated expertise.
2. User intent alignment
Searchers looking for information about a specific treatment or condition may prefer comprehensive pages about that topic over pages that briefly mention it alongside dozens of other topics. Better engagement metrics could reinforce rankings.
3. Confounding variables
Sites ranking #1 likely have stronger backlink profiles, higher domain authority, and greater brand recognition. The content depth pattern could be correlation rather than causation well-resourced sites that already rank well may simply invest more in content development.
4. Reverse causation
Sites that already rank well may invest in deeper content because they can afford to. Sites struggling to rank may try to compensate by covering more keywords, hoping to capture traffic from multiple queries.
This analysis shows correlation, not causation. Sites ranking #1 have many advantages beyond content characteristics, and isolating the impact of any single factor isn’t possible from this data alone.
Practical Implications
If these patterns reflect something meaningful about ranking dynamics in healthcare search:
1. Focus depth over breadth on individual pages
Rather than mentioning every related keyword on a single page, consider covering core topics thoroughly. The data suggests pages ranking #1 average over 1,000 words per entity mentioned deep coverage of focused topics.
2. Create topic-specific pages
Instead of one comprehensive page covering all treatments and conditions, consider dedicated pages for each major topic. Let each page go deep on its specific subject.
3. Use site architecture for breadth
Build site-wide comprehensiveness through internal linking and content architecture rather than cramming all keywords onto individual pages. The “entity coverage” can exist at the site level while individual pages maintain focus.
4. Reconsider keyword density approaches
Entity density (entities per 1,000 words) showed no meaningful correlation with rankings. Cramming more keywords into the same amount of content doesn’t appear to help and may hurt.
Limitations
This analysis has significant constraints:
Single vertical: Healthcare and addiction treatment only. Patterns may differ substantially in other industries with different competitive dynamics, user intent patterns, and quality signals.
Correlation only: No causal claims can be made. The analysis identifies patterns but cannot determine whether content characteristics influence rankings or merely correlate with other factors that do.
Small effect sizes: All correlations explain less than 1% of variance in rankings. Statistical significance with large samples doesn’t imply practical significance. Many other factors dominate ranking outcomes.
Confounders not controlled: Domain authority, backlink profiles, brand recognition, technical SEO, and user behavior signals were not measured. These likely explain far more variance than content characteristics.
Point-in-time snapshot: Rankings were captured in December 2024. SERP positions fluctuate, and patterns may change over time.
Entity detection method: Keyword-based matching may miss semantic variations and could over-count phrases appearing in navigation or boilerplate content.
Crawl depth limits: The 15-page limit may underrepresent large sites, potentially biasing entity counts for domains with extensive content libraries.
Summary
In this healthcare SERP dataset, Position #1 results tend to have:
• Fewer total entity mentions than lower positions
* Substantially more words per page (+61% vs Position #10)
* Higher word-to-entity ratios (+89% vs Position #10)
The pattern suggests that at least in this vertical comprehensive coverage of fewer topics may correlate with better rankings than shallow coverage of many topics.
Whether this reflects Google’s ranking preferences, user behavior signals, or confounding factors from domain authority remains an open question. The effect sizes are small, and many factors beyond content characteristics influence rankings.
The practical takeaway may be simple: don’t try to be comprehensive on every page. Write deeply about focused topics and use site architecture to create breadth.
Dataset: 999 healthcare queries • 9,879 search results • 2,110 domains • 25,781 pages crawled • Matched-sample statistical analysis (n=317 per group) • December 2025
WillDoSEO.com
